Tutorials
Protocols
Learn More
Resource database in UVM
The UVM centralized resource database is used to store configurable objects, variables, virtual interfaces, queues, class handles, etc., and retrieve them from the database. Such a configurable testbench provides a degree of freedom to the verification engineer to use provided information in various parts of the testbench.
Resource database mechanism
The resource database consists of polymorphic resource containers that store each resource in the form of a lookup table, a centralized resource database.
The uvm_resource_base and uvm_resource as shown below are uvm source code snippets.
uvm_resource_base class
virtual class uvm_resource_base extends uvm_object;
protected string scope;
int unsigned precedence;
static int unsigned default_precedence = 1000;
...
...
endclassuvm_resource class
class uvm_resource #(type T=int) extends uvm_resource_base;
typedef uvm_resource#(T) this_type;
static this_type my_type = get_type();
...
...
endclassThe uvm_resource_base class is a common base class for the resource container family that defines a set of functions. The uvm_resource#(type T) is a parameterized class that provides additional functions like read() and write() for resource operation.
Each resource has a set of scope. A scope is a context like an instantiation of the component in the uvm testbench hierarchy that represents a unique string (For example tb_top.env.agent_o.mon). A scope may also use uvm_object::get_full_name().
A set of scope is represented as a regular expression. For simplicity, a set of strings can be said to be a set of scope (For example regular expressions like tb_top\.env\.agent_o.* that involve strings tb_top.env.agent_o.mon and tb_top.env.agent_o.drv etc). There can be an ‘N’ set of strings (scope) in the testbench hierarchy.
Precedence variable is associate precedence of resource w.r.t. other resources when scope and name match for the resource on looking up in the database. The variable default_precedence is used to set the default precedence value initially i.e. 1000. It is allowed to change the precedence value. When two resources have the same precedence, the first resource found has a priority.
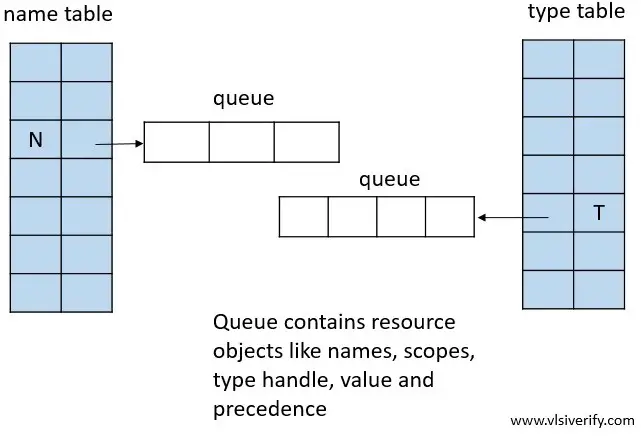
Resource database organization
The resource database consists of a pair of associative array names as ‘name table’ and ‘type table’. The ‘name table’ and ‘type table’ are alternatively known as ‘name map’ and ‘type map’. The resource is stored in the ‘name table’ by name and in the ‘type table’ by type handle. Both the name and queue table has a queue associated with them. If more than one resource has the same name or type, it is stored in the corresponding queue.
Note: The resource database is also known as the resource pool.
Adding resource entry in the database
- Check for the name in the name table. If it exists, insert resource handle into a queue based on queue handle, otherwise create a new queue for that name to put resource handle
- Similarly, check for the type handle in the type table. If it exists, insert a resource handle into a queue based on the queue handle, otherwise create a new queue for that type to put a resource handle.
Searching resource in the database
The searching in the resource database depends on
- Looking up for a resource by name or by type.
- Precedence of the resource
- The order in which resource was added in the queue.
Search in the database involves below steps
- The resource is located in the database by resource name, type, and scope. The scope represents a string that initiates the resource search.
- For name-based search, the resource name is used to locate the queue in the name table which contains a set of resources with the same name.
- If the queue is empty (i.e. no resource available in the queue) results in search fail and return null.
- If the queue is non-empty, then the queue is traversed from the back for each resource available in the queue. Based on the precedence value for the resource available in the current scope, it returns the target resource. If more resources have the same precedence value then the target resource will be the earliest in the queue.
- If the queue is non-empty and the target resource is not found in the queue, results in search fail and return null.
- For type-based search, the same steps are followed.
Auditing
The auditing capability in the resource database is used to track activity during the execution. Auditing collects two sets of information.
- A set of access records
- A set of collected information as to get records
A set of access records: Each resource is accessed by either read or write. For each time resource access is made, the accessor is given by the user. Typically, it is given as ‘this’. The auditing facility in uvm resource provides facilities
- To store time for last read, last write, number of reads, number of writes.
- To track the name of an object from which the resource was accessed.
A set of collected information to get records: The record has information about the name of the object being looked up, time of the lookup, the resource handle, and the supplied scope information. This information is helpful to determine whether the testbench is configured properly or not. This information is typically dumped at the end of the simulation.
UVM Tutorials